tl;dr: Adding layers to build a deep model is exponentially better than just increasing the number of parameters in a shallow one in order to increase the complexity of the piecewise linear functions computed by feedforward neural networks with rectifier or maxout networks.
Consider a feed forward neural network with linear layers $f_{l} (x) = W^l x + b^l$ followed by ReLUs $g_{l} (z) = \max \lbrace 0, z \rbrace $:
\[ F = f_{\operatorname{out}} \circ g_{L} \circ f_{L} \circ \ldots g_{1} \circ f_{1} . \]
Each unit $i$ of layer $l$ is linear at each side of the hyperplane $H_{i} = \ \lbrace W^l_{i :} x + b^l = 0 \rbrace $, where $g$ changes from 0 to the identity. The collection of al $H_{i}$ therefore splits the space of inputs to this layer into open, connected (and convex) sets. These are called linear regions for $g_{l} \circ f_{l}$. More generally:
Definition 1: A linear region of a piecewise linear function $F : \mathbb{R}^{n_{0}} \rightarrow \mathbb{R}^m$ is a maximal connected subset of the domain $\mathbb{R}^{n_{0}}$ where $F$ is linear.
The reason why these regions are important is that they measure how rich a piecewise linear function is, so the more of these (per number of layers or of parameters) a network can exhibit, the richer the set of functions it can approximate. Note that by adding more units to a single layer network, one can achieve any given number of linear regions; what matters is that adding layers while keeping fixed the number of parameters exponentially increases this number.
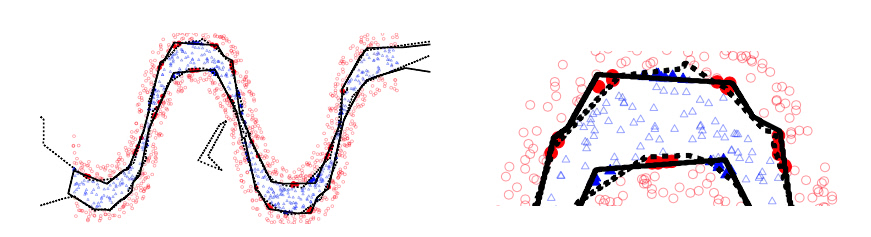
Decision boundaries of 1 and 2 layer models with the same number of hidden units
We will be discussing lower bounds on the number of such linear regions for the full network $F$ as a function of the number of layers $L$ and of the number of parameters. In addition to rectifier activations, maxout is studied.1
It was already known that deep networks with ReLUs split their input space into exponentially more linear regions than shallow networks, more specifically:
Theorem: (Pascanu et al. 2013)2 A rectifier neural network with $n_{0}$ inputs and $L$ hidden layers of width $n \geqslant n_{0}$ can compute functions that have $\Omega ((n / n_{0})^{L - 1} n^{n_{0}})$ linear regions.
The first contribution of the current paper is an improvement over this result with a bound which is also exponential in $n_{0}$:
Theorem 2: A rectifier neural network with $n_{0}$ inputs and $L$ hidden layers of width $n \geqslant n_{0}$ can compute functions that have $\Omega ((n / n_{0})^{(L - 1) n_{0}} n^{n_{0}})$ linear regions.
This seems a small improvement at first glance, but it implies that even for $L$ and $n$ small, deep models are able to compute functions with a significantly greater amount of linear regions than shallow models can,3 which is in tune with experimental evidence.
The second contribution of the paper is the application to maxout networks, which again shows a growth of the number of linear regions which is exponential in $L$.
Theorem 3: A maxout network with $L$ layers of constant width $n_{0}$ and rank $k$ can compute functions with at least $k^{L - 1} k^{n_{0}}$ linear regions.
By translating this theorem into a dependency on the number of parameters $K$ it is possible to see that the growth in linear regions is exponential in $K$ for deep models whereas it is only polynomial for shallow ones.
To conclude the authors note:4
This framework is applicable to any neural network that has a piecewise linear activation function. For example, if we consider a convolutional network with rectifier units, as the one used in (Krizhevsky et al. 2012), we can see that the convolution followed by max pooling at each layer identifies all patches of the input within a pooling region. This will let such a deep convolutional neural network recursively identify patches of the images of lower layers, resulting in exponentially many linear regions of the input space.
- Maxout activations take the maximum over several units. See Maxout Networks . ⇧
- On the number of response regions of deep feed forward networks with piece-wise linear activations, (2013) . ⇧
- Note that Pascanu et al. already mentions a similar fact. One wonders… ⇧
- It seems to me that the condition $n_{i} \geqslant n_{0}$ would be violated in convnets. Why is this statement valid? ⇧