tl;dr:1 deep convnets avoid the curse of dimensionality for the approximation of certain classes of functions (hierarchical compositions): complexity bounds (for the number of units) are polynomial instead of exponential in the dimension of the input as is the case for shallow networks. This is true for smooth and non-smooth activations like ReLUs. For the latter insight into how they approximate (hierarchical) Lipschitz functions is provided . It is conjectured that many target functions relevant to current machine learning problems are in these classes due either to physical grounds2 or biological ones.
Guarantees of the approximation properties of NNs are typically proven for general classes of functions, say $C^m (X), X \subseteq \mathbb{R}^n$ or assuming weaker regularity, like some Sobolev space $W^{m, p} (X)$. Without additional restrictions, not only can the approximation performance not be guaranteed to be good, but it can be guaranteed to be bad.3
An old and powerful insight into why convnets work so well is the fact that they are hierarchical compositions of local functions. They look like:
\[ f (x_{1}, \ldots, x_{8}) = h_{3} (h_{21} (h_{11} (x_{1}, x_{3}), h_{12} (x_{2}, x_{4})), h_{22} (h_{13} (x_{5}, x_{6}), h_{14} (x_{7}, x_{8} ))) . \]
The hierarchical structure is obvious; we can represent the compositions as a $d$-tree: every non-leaf node has $d$ inputs and one output, with $d = 2$ (i.e. a binary tree) and $8$ leafs at the bottom. We say that $f$ has $d$-tree structure. The term locality refers to the lower dimension $d \ll n$ of the domain of each constituent function $h_{i j}$. Since convnets are exactly of this type, it seems sensible to restrict oneself to general classes of functions which keep this structure to investigate why deep convnets excel where shallow nets fail. The idea is to prove:
- Deep convnets approximate hierarchical, compositional functions arbitrarily well, with polynomial cost in complexity.
- Shallow nets might incur a huge complexity penalty in approximating these functions (upper bounds) and they actually do in many cases (lower bounds).
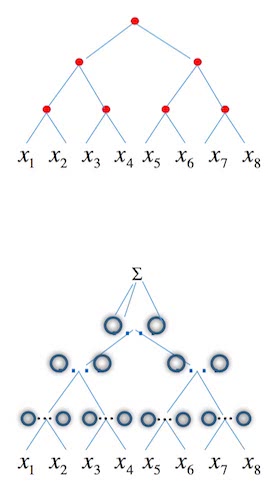
A function with binary tree structure and an ideal network approximating it.
Of course the obvious question is why this kind of functions are relevant in practice! Here are two hypotheses to this respect:
- Lin and Tegmark4 recently proposed that physical processes relevant to ML tasks are described by simple, polynomial, Hamiltonians (at different scales). These are very easily approximated by hierarchical neural networks, since multiplication is.
- The authors of the review propose a sort of (weak) anthropic principle: ML focuses on many problems which are well solved by the brain, and the brain is wired in a deep, hierarchical way because it was evolutionarily advantageous. Therefore it is reasonable that hierarchical deep networks perform well at the same tasks.5
But let us get to (some of) the results. We can formalize the previous notions
as follows. Note that we must change their notation a bit because it collides
with otherwise common sense notation.
Some definitions
Definition 1: Let $V_{N}$ be the set of all networks with total number of units (complexity) $N$ and $f \in W$, for some function set $W$. The degree of approximation of $V_{N}$ to $f$ is
\[ \operatorname{dist} (f, V_{N}) = \underset{P \in V_{N}}{\inf} | f - P |_{\infty} . \]
Then, if $\operatorname{dist}(f, V_{N}) =\mathcal{O}(N^{- \gamma})$ for some $\gamma > 0$, then for any $\varepsilon > 0$ there exists a network with complexity $N =\mathcal{O} \left( \varepsilon^{- 1 / \gamma} \right)$ which approximates $f$ with accuracy at least $\varepsilon$.
The restricted function spaces to consider will be characterised by their smoothness and “degree of compositionality” $d$. The paper first handles the case $d = 2$, then goes on to arbitrary but fixed $d$ (Theorem 3), then to variable $d$ across units (Theorem 6).
Definition 2: Let $S_{N}^n \subset V_{N}$ be the class of all shallow networks with $n$ inputs and $N$ hidden units of the form
\[ x \mapsto \sum_{k = 1}^N a_{k} \sigma (\langle w_{k}, x \rangle + b_{k}), \quad w_{k} \in \mathbb{R}^n, b_{k} \in \mathbb{R}, \]
with $\sigma$ a smooth non-polynomial non-linearity.
Let $D_{N, d}^n \subset V_{N}$ be the class of all deep networks (i.e. having more than one hidden layer) with a $d$-tree architecture whose nodes are all in $S_{M}^d$, where $M = N / | V |$ and $V$ is the set of non-leaf vertices of the tree.
For a convnet, $d$ is the size of the kernel, which for now we consider fixed. Each hidden unit of a network in $D_{N, d}^n$ has $d$ inputs, and $M$ sets of coefficients $a_{k}, w_{k}, b_{k}$.
Note that the smoothness assumption on $\sigma$ can be easily overcome for most non-linear activations since they can be approximated in the $| \cdot |_{\infty}$ norm by smooth ones, e.g. the ReLU can be trivially approximated by piecing together two linear functions and a polynomial, or more generally with splines. See more on this below.
Smooth activation functions
Equipped with these definitions we come to the main result (which is not in this exact form in the paper)
Theorem 3: Let $f \in C^m (X_{n})$ with $n = \dim X_{n}$. Then a shallow network in some $S_{N}^n$ approximating $f$ with accuracy $\varepsilon > 0$ has complexity
\[ N =\mathcal{O} (\varepsilon^{- n / m}) . \]
and this is the best possible $N$.
If we assume that $f$ has $d$-tree structure, then a deep network in some $D_{N, d}^n$ which approximates $f$ with accuracy $\varepsilon > 0$ has complexity
\[ N =\mathcal{O} ((n - 1) \varepsilon^{- d / m}) . \]
The proof of the second part of the theorem is quite straightforward, given the first (which is known at least since Approximation theory of the MLP model in neural networks, (1999) ) and starting from a network which mimics the compositional structure of $f$. Noting that each of the units of the deep network is a a shallow one with $n = d$ inputs, which approximates the corresponding compositional unit of $f$ within $\varepsilon$, one need only apply the triangle inequality $n - 1$ times and a Lipschitz bound to conclude.6 Note that
the deep network does not need to have exactly the same compositional architecture as the compositional function to be approximated. It is sufficient that the acyclic graph representing the structure of the function is a subgraph of the graph representing the structure of the deep network.
Let us state that again: when we assume that we want to approximate (smooth) functions with $d$-tree structure and use deep networks with analogous structure we only pay a polynomial price in complexity for an increase in input dimension.
This leads to the following
Definition 4: The effective dimension of a class $W$ of functions (for a given norm) is said to be $d$ if for every $\varepsilon > 0$, any function in $W$ can be recovered within an accuracy of $\varepsilon$ (as measured by the norm) using an appropriate network (either shallow or deep) with $C \varepsilon^{- d}$ parameters with $C =\mathcal{O} (N)$.7
For example the effective dimension of $m$-times continuously differentiable functions of $n$ variables is $n / m$ and that of those which in addition have $d$-tree structure is $d / m$. Also the effective dimension of $\operatorname{Lip} (\mathbb{R})$ is 1 and that of $\operatorname{Lip} (\mathbb{R}^2)$ is 2. As an example of the reduction of effective dimension by compositionality, consider the function $x, y \mapsto | x^2 - y^2 |$. It is Lipschitz of two variables, but if we see it as the composition of a polynomial in $P_{2}^2$ and the norm function, which is in $\operatorname{Lip} (\mathbb{R})$, one can show that a bi-layer network can approximate it with $\mathcal{O} (\varepsilon^{- 1})$.
We come now to a more general version of Theorem 3, where the degree of compositionality is allowed to vary across nodes in the network as is typically the case in convnets, whose kernels are of varying sizes. Compositional functions are thus generalized to having the structure of any DAG $\mathcal{G}$ and are called $\mathcal{G}$-functions.
Theorem 5: Assume $f \in C^m$ is a $\mathcal{G}$-function for some DAG $\mathcal{G}$. Let $V$ be the set of non-input nodes of $\mathcal{G}$, $m_{v}$ the smoothness of the constituent function for $f$ at node $v$ and $d_{v}$ the in-degree of $v$. Fix an accuracy $\varepsilon > 0$. Then for any shallow network approximating $f$ with $\varepsilon$ accuracy, its complexity is
\[ N_{s} =\mathcal{O} (\varepsilon^{- n / m}), \]
where $m = \min _{v \in V} m_{v}$. However, for a deep network:
\[ N_{d} =\mathcal{O} \left( \sum_{v \in V} \varepsilon^{- d_{v} / m_{v}} \right) . \]
Using ReLUs
The following extension of Theorem 3 should follow by a simple approximation argument. Note that the statement in the paper omits the condition that $f$ be $d$-compositional, but it should be there!
Theorem 6: Let $f$ be an $L$-Lipschitz function of $n$ variables with $d$-tree structure. Then, the complexity of a shallow network which is a linear combination of ReLUs providing an approximation with accuracy at least $\varepsilon > 0$ is
\[ N_{s} =\mathcal{O} \left( \left( \tfrac{\varepsilon}{L} \right)^{- n} \right) \]
whereas that of a deep (binary) compositional architecture is
\[ N_{d} =\mathcal{O} \left( (n - 1) \left( \tfrac{\varepsilon}{L} \right)^{- d} \right) . \]
Furthermore Appendix 4 of the paper provides an explicit construction for the piecewise approximation of Lipschitz functions. There it is shown that multilayer ReLU networks can perform piecewise constant approximation of (hierarchical compositions of) Lipschitz functions. The authors
conjecture that the construction (…) that performs piecewise constant approximation is qualitatively similar to what deep networks may represent after training
because of the greedy way in which supervised training proceeds and how it relates to their construction.
Gaps
We have seen that shallow networks will perform badly for general continuous functions and that deep hierarchical nets will perform very well (polynomial complexity) for hierarchical targets. But what are specific examples of functions which reveal the gap in performance? There are many such examples and the authors cite several and provide their own, see Section §4.2 in the paper.
One can also ask the question of when functions generated by deep architectures cannot be efficiently (with a comparable number of units) generated by shallower networks. See Why does deep and cheap learning work so well? for concrete examples of such no-flattening theorems: the fact that certain deep architectures cannot be made shallower without incurring an exponential penalty in the number of inputs. In particular, Lin and Tegmark prove that this is the case for multiplication, which is “the prototypical compositional function”.
Discussion on compositionality
Section §6 of the paper is devoted to a long list of observations on compositionality, approximation, sparsity, multi-class classification, DNNs as memories and general considerations from the perspective of the theory of computation. Just read it.
- This paper is packed with results, comments and conjectures! I had to omit many details to keep this post at a reasonable length. ⇧
- Why does deep and cheap learning work so well? . ⇧
- For approximation to continuous functions by shallow networks, Approximation theory of the MLP model in neural networks, (1999) (§6), cites results by Maiorov on the upper and lower bounds on the approximation quality which are exponential on the number of inputs and the “bad functions” guilty of the lower bound actually form a set of “large measure” so this is not just a worst-case scenario. As a matter of fact: “examples of specific functions that cannot be represented efficiently by shallow networks have been given very recently by Telgarsky [25] and by Shamir [26]. [The authors] provide in theorem 5 another example (…) for which there is a gap between shallow and deep networks.“ ⇧
- See Why does deep and cheap learning work so well? . ⇧
- Did that make any sense? ⇧
- Sloppily: Assume $P, P_{i}$ approximate $h, h_{i }$ within $\varepsilon$, then compute $| h (h_{i}, h_{j}) - P (P_{i}, P_{j}) |_{\infty} \leqslant | h(h_{i}, h_{j}) - h (P_{i}, P_{j}) |_{\infty} + | h (P_{i}, P_{j}) - P(P_{i}, P_{j}) |_{\infty} \leqslant L | (h_{i}, h_{j}) - (P_{i},P_{j}) | + c \varepsilon \lesssim \varepsilon$. ⇧
- I added this last bit with $C =\mathcal{O} (N)$ for better consistency with the main result. It is the exponent what matters in the definition. ⇧